文字列と文字(Strings and Characters)
最終更新日: 2025/6/28
原文: https://docs.swift.org/swift-book/LanguageGuide/StringsAndCharacters.html
テキストを保存して操作する。
文字列 は "hello, world" や "albatross" のような一連の文字です。Swift の文字列は String 型で表されます。String の内容には、様々な方法でアクセスすることができます(Character 型の値のコレクションとしてなど)。
Swift の String と Character 型は、高速で、Unicode に準拠した方法でテキストを扱うことができます。文字列の生成と操作の構文は、C 言語に似た文字列リテラルの構文を使い、軽量で読みやすくなっています。文字列の連結は、+ 演算子を使用して 2 つの文字列の連結をするシンプルなものです。また、文字列が変更が可能かどうかは、他の型と同じように定数か変数かを選択することで管理できます。また、文字列補間と呼ばれるプロセスの中で、定数、変数、リテラルや式をより長い文字列の中に入れることができます。こういった特徴から、表示用、ストレージ用、出力用などにカスタム文字列も簡単に作ることができます。
このようなシンプルな構文にもかかわらず、Swift の String 型は、高速で、モダンな実装になっています。それぞれの文字は、特定の変換形式とは独立した Unicode 文字群で構成され、様々な Unicode 形式でアクセスできるようになっています。
NOTE
Swift のString型は、Foundation のNSStringクラスとスムーズにやりとりできるようにしています。同様に、Foundation でもNSStringで定義されたメソッドを使用できるようにするために、Stringを拡張しています。つまり、Foundation をインポートすると、キャストなしでNSStringのメソッドにStringからアクセスできます。 Foundation と Cocoa を使ったStringの使用方法に関しては、Bridging Between String and NSStringを参照ください
文字列リテラル(String Literals)
事前に定義された String を 文字列リテラル として使用することができます。文字列リテラルはダブルクォーテーション(")で囲まれた一連の文字です。
let someString = "Some string literal value"
someString は文字列リテラルで初期化されているので、String 型と推論されていることに注目してください。
複数行文字列リテラル(Multiline String Literals)
複数行に渡った文字列が必要な場合、複数行文字列リテラルを使いましょう。一連の文字を 3 つのダブルクォーテーション(")で囲みます。
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
複数行文字列リテラルは、全てを開始と終了のクォーテーションマークの間に含めます。文字列は、開始クォーテーションの次の行から始め、終了クォーテーションの 1 つ前の行で終了します。つまり、文字列を改行で開始、終了することができません。
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""
もし改行が含まれている場合、文字列にも反映されます。改行を文字列の中に入れずに改行したい場合、行の最後にバックスラッシュ(\)を書きましょう:
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
複数行文字列リテラルを改行で開始(終了)したい場合は、最初(最後)に空白の行を入れましょう。例えば:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
複数行文字列は、周りのコードに合わせてインデントさせることができます。終了クォーテーションマーク(""")の前に空白を加えると、他の行に存在する同じ位置の空白も無視するようになります。一方で、終了クォーテーションマーク(""")の空白のさらに後に空白を追加すると、その行の空白 は 含まれるようになります。

上記の例では、全ての複数行文字列にインデントが加えられていますが、最初と最後の行は冒頭に空白はありません。真ん中の行は終了クォーテーションマーク(""")よりもさらにインデントを追加しているため、4 つの空白から開始します。
文字列内の特殊文字(Special Characters in String Literals)
文字列リテラルには次の特殊文字が含まれています。
- エスケープされた特殊文字
\0 (null文字)、\\ (バックスラッシュ)、\t (水平タブ)、\n (ラインフィード)、\r (キャリッジリターン)、\" (ダブルクォーテーション)、\' (シングルクォーテーション) \u{n}で書ける任意の Unicode スカラ、ただしnには 1〜8 桁の 16 進数が入ります(Unicode については下記のUnicodeに書かれています)
下記のコードは、4 つの特殊文字の例を示しています。wiseWords 定数は 2 つのエスケープされたダブルクォーテーションを含んでいます。dollarSign と blackHeart と sparklingHeart 定数は、Unicode スカラの例です:
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" // $ Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥ Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖 Unicode scalar U+1F496
複数行文字列リテラルは 1 つではなく 3 つのダブルクォーテーションを使用しているので、複数行文字列リテラルの中にエスケープなしでダブルクォーテーションを含めることができます。文字列にテキストとして """ を含めたい場合、少なくともその中の 1 つをエスケープしてください。
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""
拡張区切り文字(Extended String Delimiters)
拡張区切り文字 の中に文字列を置くと、特殊文字をただの文字として含めることができます。文字列をクォーテーションで囲み、さらにそれを 番号記号 で囲みます。例えば、#"Line 1\nLine 2"# は 2 行の文字列を出力するのではなく、改行コード(\n)を出力します。
文字列内の文字に特殊効果を付けたい場合は、エスケープ文字(\)の後に囲んでいる番号記号と同じ番号記号を、同じ数追加してください。例えば、#"Line 1\nLine 2"# で、改行したい場合は、#"Line 1\#nLine 2"# と書くことができます。同様に、###"Line1\###nLine2"### でも改行することができます。
拡張区切り文字は複数文字列リテラルにも使用できます。テキストとして """ を含めたい場合、文字列を終わらせる記号を変えましょう。例えば:
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
"""#
空の文字列の作成(Initializing an Empty String)
長い文字列を構築するときに、初期値として空の文字列を作るとき、文字列リテラルを変数に設定するか、String のイニシャライザを使用して新しいインスタンスを初期化します。
var emptyString = "" // 空の文字列
var anotherEmptyString = String() // イニシャライザ
// 2つの変数はどちらも空の文字列で等しいです
isEmpty というブール値のプロパティをチェックすることで String が空文字かどうかを判定できます。
if emptyString.isEmpty {
print("Nothing to see here")
}
// Nothing to see here
文字列の可変性(String Mutability)
String が変更可能かどうかは、変数(変更可能)か定数(変更不可能)のどちらに設定するかによって示すことができます:
var variableString = "Horse"
variableString += " and carriage"
// variableString は "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// コンパイルエラー - 定数は変更できません
NOTE
これは Objective-C と Cocoa とは異なります。Objective-C と Cocoa では、変更の可不可を示すために 2 つのクラス(NSStringとNSMutableString)から選択します。
文字列は値型(Strings Are Value Types)
String 型は 値型 です。新しい String を生成すると、関数やメソッドのパラメータで渡されるときや、他の定数、変数に代入されるときに、値のコピーが発生します。いずれの場合でも、既存の String のコピーが生成され、元の値ではなく新しいコピーが渡され(または代入され)ます。値型はStructures and Enumerations Are Value Types(構造体と列挙型は値型)で記載されています。
Swift の、デフォルトでコピーをする String の挙動は、String が関数やメソッドのパラメータで渡されるときに、どこからその値が来たとしても、正しい String を所有していることが保証されます。つまり、渡された文字列は、自身で変更しない限り決して変更されることがありません。
内部では、Swift のコンパイラは本当に必要なときだけ実際にコピーが発生するように最適化をしています。つまり、値型として文字列を扱う場合に常に良いパフォーマンスを得ることができます。
文字配列の取扱(Working with Characters)
for-in ループを使用して文字列を繰り返し処理することで、String の個々の Character にアクセスすることができます。
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶
for-in ループについてはFor-In Loops(For-In ループ)に記載されています。
もしくは、Character の型注釈を与えて 1 文字のリテラルから Character 型の定数や変数を作ることもできます:
let exclamationMark: Character = "!"
String は、Character の配列をイニシャライザの引数として渡して構築することができます:
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// Cat!🐱
文字と文字列の連結(Concatenating Strings and Characters)
String 同士は、加算演算子(+)使用して新しい String を生成できます:
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcome は "hello there" と等しい
加算代入演算子(+=)を使用して、既存の String 変数に String を追加することもできます:
var instruction = "look over"
instruction += string2
// instruction は "look over there" と等しい
String の append() メソッドを使用して Character を追加することもできます。
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcome は "hello there!" と等しい
NOTE
既存のCharacterにStringやCharacterを追加することはできません。Characterには、 1 つの文字だけしか含められません。
より長い文字列を構築するために複数行文字列リテラルを使用している場合、最後の行も含めた全ての行で改行したいこともあるかと思います。例えば:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// two lines:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// three lines:
// one
// two
// three
上記のコードは、badStart と end を連結すると、2 行の文字列を生成していますが、これは期待した結果ではありません。badStart の最後の行に改行が入っていないため、end の最初の行と混ざってしまいます。一方で、goodStart の最初と最後の行は改行で終わっているので、end と連結した結果は 3 行になり、期待通りになります。
文字列補間(String Interpolation)
文字列補間 は、複数の定数、変数、リテラル、式を文字列リテラルの中に含めることで新しい String を構築する方法です。文字列補間は 1 行でも複数行でも使用することができます。文字列に入れるそれぞれの値は、両括弧で囲み、その前にバックスラッシュ(\)をつけます。
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message は "3 times 2.5 is 7.5"
上記の例では、multiplier は \(multiplier) として文字列に挿入します。このプレースホルダは、実際に文字列を生成するタイミングで評価され、multiplier の実際の値に置き換えられます。
multiplier は文字列の後半の大きな式の中でも使われています。この式は、Double(multiplier) * 2.5 を計算して、その結果の(7.5)を文字列に挿入します。この場合、\(Double(multiplier) * 2.5) と書いて文字列リテラルに含まれます。
文字列補間ではなく通常扱われる文字として文字列を生成したい場合、拡張区切り文字を使用することができます。例えば:
print(#"Write an interpolated string in Swift using \(multiplier)."#)
// Write an interpolated string in Swift using \(multiplier).
拡張区切り文字を使った文字列の中で文字列補間を使用する場合、バックスラッシュの後の番号記号の数を文字列の開始(終了)の番号記号の数に合わせます。例えば:
print(#"6 times 7 is \#(6 * 7)."#)
// 6 times 7 is 42.
NOTE
補間された文字列内の括弧の中に書かれた式には、エスケープしていないバックスラッシュ(\)、キャリッジリターン、改行を含めることはできません。他の文字列リテラルは含めることができます。
Unicode
Unicode は、様々な書記体系で、テキストをエンコード、抽象化、および処理するための国際標準です。標準化された形式で、どんな言語でもほとんど全ての文字を表わすことができ、Web ページやテキストファイルなどの外部リソースへ読み書きできます。Swift の String や Character は、このセクションでも記載していますが、完全に Unicode に準拠しています。
Unicode スカラ値(Unicode Scalar Values)
内部では、Swift 固有の String 型は Unicode スカラから構築されています。Unicode スカラは 21 ビットの文字と修飾子で構成されています。例えば、U+0061 は LATIN SMALL LETTER A ("a")、U+1F425 は FRONT-FACING BABY CHICK ("🐥") です。
全ての 21 ビットのスカラが 1 つの文字に当てはまるわけではありません。いくつかは将来的に必要になるために確保されていたり、UTF-16 で使われています。文字に割り当てられているスカラには、上記の LATIN SMALL LETTER A や FRONT-FACING BABY CHICK のように一般的には名前が付いています。
拡張書記素クラスタ(Extended Grapheme Clusters)
Swift の Character の全てのインスタンスは 1 つの 拡張書記素クラスタ を表しています。拡張書記素クラスタは、人間が読み取れる 1 文字を生成するための 1 つ以上の Unicode スカラの配列です(1 つ以上の Unicode スカラが必要な場合は合成されます)。
次に例を示します。文字 é は、1 つの é(LATIN SMALL LETTER E WITH ACUTE または U+00E9)を表すことができます。一方で、同じ文字をスカラのペアで表すこともできます。e(LATIN SMALL LETTER E または U+0065)の後ろに COMBINING ACUTE ACCENT スカラ(U+0301)を付けます。COMBINING ACUTE ACCENT スカラはその前のスカラに視覚的に適用されて、Unicode を理解できるシステムがテキストをレンダリングする際に、e を é に変換します。
どちらの場合も、é は拡張書記素クラスタの 1 つの Character 型の値として表されます。最初のケースでは、1 つのスカラを含んでいるクラスタで、2 番目のケースは、2 つのスカラのクラスタとなります。
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e の後ろに ́
// eAcute は é, combinedEAcute は é
拡張書記素クラスタは、多くの複雑な文字スクリプトを 1 つの Character として表す柔軟な方法です。例えば、韓国語のハングル文字は、合成または展開されたスカラの配列で表すことができます。これらのどちらも、 Swift では 1 つの Character と見なされます。
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed は 한, decomposed も 한
拡張書記素クラスタは、囲み記号(COMBINING ENCLOSING CIRCLE または U+20DD)のスカラを 1 つの Character の一部として、他の Unicode スカラを囲むことができます。
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute is é⃝
地域を示す Unicode スカラは、1 つの Character を作成するために、2 つのスカラを組み合わせます。例えば、REGIONAL INDICATOR SYMBOL LETTER U(U+1F1FA)と REGIONAL INDICATOR SYMBOL LETTER S(U+1F1F8):
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUS は 🇺🇸
文字数を数える(Counting Characters)
文字列の中の Character の数を得るには、文字列の count プロパティを使いましょう。
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// unusualMenagerie has 40 characters
Character に拡張書記素クラスタを使用しているということは、文字列の連結や変更が必ずしも文字列内の文字数に影響を与えるわけではない、ということに注意してください。
例えば、cafe という単語は 4 つの文字から新しい文字列を初期化した場合、COMBINING ACUTE ACCENT (U+0301) を最後に追加すると、最後の文字は e から é に変わりますが、文字のカウントは 4 のままです。
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// the number of characters in cafe is 4
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// the number of characters in café is 4
NOTE
拡張書記素クラスタは複数の Unicode スカラを組み合わせることができます。つまり、異なった文字や、同じ文字でも、異なったスカラで表された文字はメモリ上に保持する際に異なったメモリサイズが必要になる場合があります。これは、Swift の文字は、それぞれの文字で同じメモリ量ではない、ということです。結果として、文字列内の文字を数えるには、拡張書記素クラスタの境界を判断しなければならず、文字列全体を繰り返し処理しないと計算することができません。特に長い文字列を扱っている場合は、countプロパティを使用すると文字数をカウントするために文字列全体に繰り返し処理を行なっていることに気をつけてください。countプロパティから返ってくる文字数は、同じ文字列であってもNSStringのlengthと異なる場合があります。NSStringのlengthは UTF-16 での文字数カウントで、Unicode の拡張書記素クラスタでの数ではありません。
文字列へのアクセスと変更(Accessing and Modifying a String)
メソッドやプロパティを使ったり、サブスクリプト構文を使用して、文字列へアクセスしたり、変更をすることができます。
文字列のインデックス(String Indices)
String は String.Index という紐づいたインデックスの型を持っており、それぞれは文字列の Character の位置と対応関係があります。
上記で述べたように、異なる文字には異なるメモリ量が必要になります。つまり、Character の位置を特定するには、Unicode スカラを文字列の最初または最後から反復して探さなければなりません。こういった理由から Swift の String のインデックスは数値にすることはできません。
String の最初の Character の位置を知るためには、startIndex プロパティを使いましょう。endIndex プロパティは String の最後の Character の位置の次の位置です。つまり、endIndex プロパティは文字列のサブスクリプトに使用してはいけません。String が空ならば、startIndex と endIndex は等しくなります。
index(before:) と index(after:) を使用して、あるインデックスの前後のインデックスにアクセスできます。あるインデックスから離れた位置のインデックスにアクセスするためには、上記 2 つのメソッドを繰り返し呼ぶのではなく、index(_:offsetBy:) を使います。
String のある特定の位置の Character へアクセスするには、サブスクリプト構文を使います。
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a
文字列の範囲を超えたインデックスや Character にアクセスしたり、実行時エラーが起きます。
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Error
文字列内の個々の文字の全てのインデックスにアクセスするためには indices プロパティを使いましょう。
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// G u t e n T a g !
NOTE
Collectionプロトコルに準拠したどんな型にも、startIndex、endIndexプロパティ、index\(before:)、index(after:)、index(_:offsetBy:)メソッドを使用することができます。これは、Array、Dictionary、Setといったコレクションの型と同様に、今紹介しているStringにも含まれています。
挿入と削除(Inserting and Removing)
特定の文字列のインデックスに 1 つの文字を挿入するには、insert(_:at:) を使い、他の文字列を挿入したい場合は、insert(contentsOf:at:) を使います。
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome は "hello!" と等しい
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcome は "hello there!" と等しい
文字列の特定のインデックスの 1 つの文字を削除するには remove(at:) を使い、部分文字列を削除したい場合は removeSubrange(_:) を使います。
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome は "hello there" と等しい
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome は "hello" と等しい
NOTE
RangeReplaceableCollectionプロトコルに準拠したどんな型にも、insert(_:at:)、insert(contentsOf:at:)、remove(at:)、removeSubrange(_:)メソッドを使用することができます。これは、Array、Dictionary、Setといったコレクションの型と同様に、今紹介しているStringも含んでいます。
部分文字列(Substrings)
文字列から部分文字列を取得した場合(例えばサブスクリプトや prefix(_:) などのメソッドを使用するなど)、Substringインスタンスが結果として取得できます。部分文字列には文字列とほぼ同じメソッドを使用することができます。つまり、部分文字列を文字列と同じような方法で扱うことができます。しかし、文字列とは異なり、部分文字列は、文字列に対して何かアクションを起こしているほんの短い間だけに使います。処理の結果をより長い期間保持するときは、部分文字列を String のインスタンスに変換します。例えば:
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning は "Hello"
// より長期で使用するためにStringへ変換
let newString = String(beginning)
文字列のように、部分文字列もそれを構成する文字配列をメモリ領域に持っています。文字列と部分文字列の違いはパフォーマンス最適化として、部分文字列は元の文字列や他の部分文字列を保持するのに使用しているメモリの一部を再利用します。(文字列にも似たような最適化がありますが、2 つの文字列のメモリが共有されている場合、それらは等しいと見なされます)この最適化によって、文字列や部分文字列が変更されるまでメモリのコピーが発生するコストに注意を払わなくて済みます。上記で述べたように、部分文字列は長期保持するには向いていません。部分文字列が元の文字列とメモリを共有しているため、元の文字列は部分文字列が使われている間はメモリ上に保持していなければなりません。
上記の例では、greeting は文字列です。つまり、文字列を構築する文字を保持したメモリ領域を持っています。beginning は greeting の部分文字列です。greeting が使用しているメモリを再利用しています。反対に、newString は文字列で、部分文字列から生成されたときに独自のメモリ領域を持ちます。下記の図はこの関係を示しています。
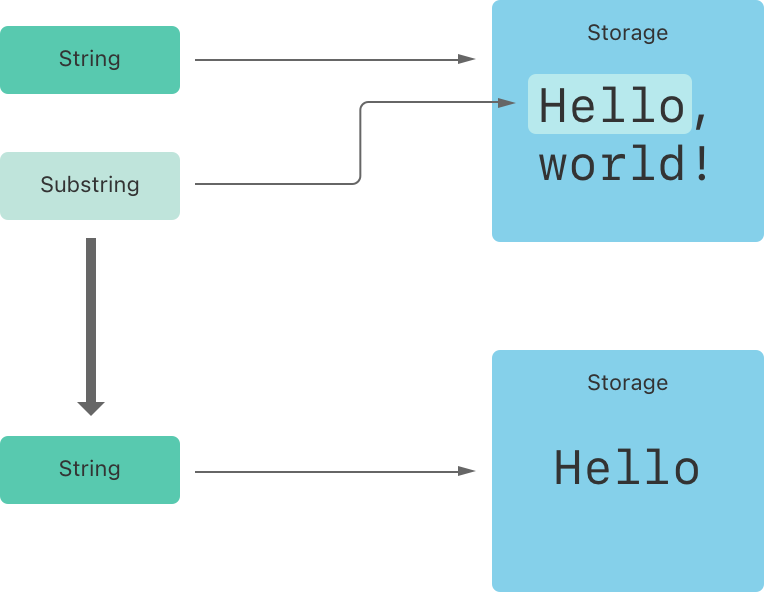
NOTE
文字列と部分文字列は、StringProtocolに準拠しています。つまり、文字列操作を行う関数は、StringProtocolの値を受け取るとしばしば便利なことがあります。文字列、部分文字列のどちらを使用しても、その関数を使用することができます。
文字列の比較(Comparing Strings)
Swift では、3 つの方法で文字列同士を比較する方法を提供しています: String または Character の完全一致、前方一致、後方一致です。
文字と文字列の等価性(String and Character Equality)
String または Character の完全一致は、は等価演算子(==)と不等価演算子(!=)を使用してチェックします。Comparison Operators(比較演算子)
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// These two strings are considered equal
2 つの文字列(または文字)は、拡張書記素クラスタが ルール上等し ければ、等しいと見なされます。つまり、内部では異なる Unicode スカラで構成されていたとしても、同じ言語的な意味と見た目が同じならば等しくなります。
例えば、LATIN SMALL LETTER E WITH ACUTE(U+00E9)は、LATIN SMALL LETTER E(U+0065)の最後に COMBINING ACUTE ACCENT(U+0301)を付け加えた文字列とルール上等しくなります。どちらの拡張書記素クラスタも é という文字を表す妥当な方法なので、これらはルール上等しいと見なされます:
// "Voulez-vous un café?"は LATIN SMALL LETTER E WITH ACUTE を使用しています
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?"は LATIN SMALL LETTER E and COMBINING ACUTE ACCENT を使用しています
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// These two strings are considered equal
反対に、英語で使われている LATIN CAPITAL LETTER A(U+0041 または "A")はロシア語で使われている CYRILLIC CAPITAL LETTER A(U+0410 または "А")と等しくありません。一見似ていますが、同じ言語的な意味を持っていません:
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters aren't equivalent.")
}
// These two characters aren't equivalent.
NOTE
Swift の文字列と文字の比較は、ロケール依存です。
前方一致と後方一致(Prefix and Suffix Equality)
ある文字列が特定の前置文字や後置文字を含んでいるかどうかをチェックするために、hasPrefix(_:) と hasSuffix(_:) メソッドを使います。どちらも 1 つの String 型の引数を受け取り、Bool 値を返します。
下記の例では、シェークスピアのロミオとジュリエットの最初の 2 幕のシーンの場所を表した文字列の配列です。
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
hasPrefix(_:) を使用して romeoAndJuliet 配列から Act 1 のシーンの数を数えます。
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// There are 5 scenes in Act 1
同様に、hasSuffix(_:) を使用して Capulet マンションや修道士ローレンスの周りで起きたシーンの数を数えてみます。
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// 6 mansion scenes; 2 cell scenes
NOTE
hasPrefix(_:)とhasSuffix(_:)メソッドは、文字ごとに各文字列の拡張書記素クラスタを使用してルール上等しいかどうかを調べます(String and Character Equality(文字と文字列の等価性)に記載)。
文字列の Unicode 表現(Unicode Representations of Strings)
Unicode 文字列は、テキストファイルや他のストレージに書かれるとき、Unicode 形式の 1 つに符号化(エンコード)されます。それぞれの形式は、文字列を コードユニット と呼ばれる小さな塊にエンコードします。これらには、UTF-8(8 ビットのコードユニットで文字列を符号化)、UTF-16(16 ビットのコードユニットで文字列を符号化)、UTF-32(32 ビットのコードユニットで文字列を符号化)があります。
Swift では、複数の Unicode 形式で文字列にアクセスできます。for-in 文で文字列を繰り返し処理する場合、Unicode 拡張書記素クラスタとして個々の Character にアクセスできます。このプロセスはWorking with Characters(文字配列の取扱)で記載しています。
他にも 3 つの Unicode 準拠形式で String にアクセスできます:
- UTF-8 のコードユニットのコレクション(
utf8プロパティを使用してアクセス) - UTF-16 のコードユニットのコレクション(
utf16プロパティを使用してアクセス) - 21 ビット Unicode スカラのコレクション、UTF-32 に等しい (
unicodeScalarsプロパティを使用してアクセス)
下記の例は、次の文字列を異なる形式で表示しています。D、 o、 g、 ‼ (DOUBLE EXCLAMATION MARK または Unicode スカラ U+203C)と 🐶 文字 (DOG FACE, or Unicode スカラ U+1F436):
let dogString = "Dog‼🐶"
UTF-8 表現(UTF-8 Representation)
UTF-8 表現には String の utf8 プロパティを使います。このプロパティの型は、String.UTF8View で、符号なし 8 ビット(UInt8)のコレクションで、文字列の UTF-8 表現のそれぞれのバイトを表しています:
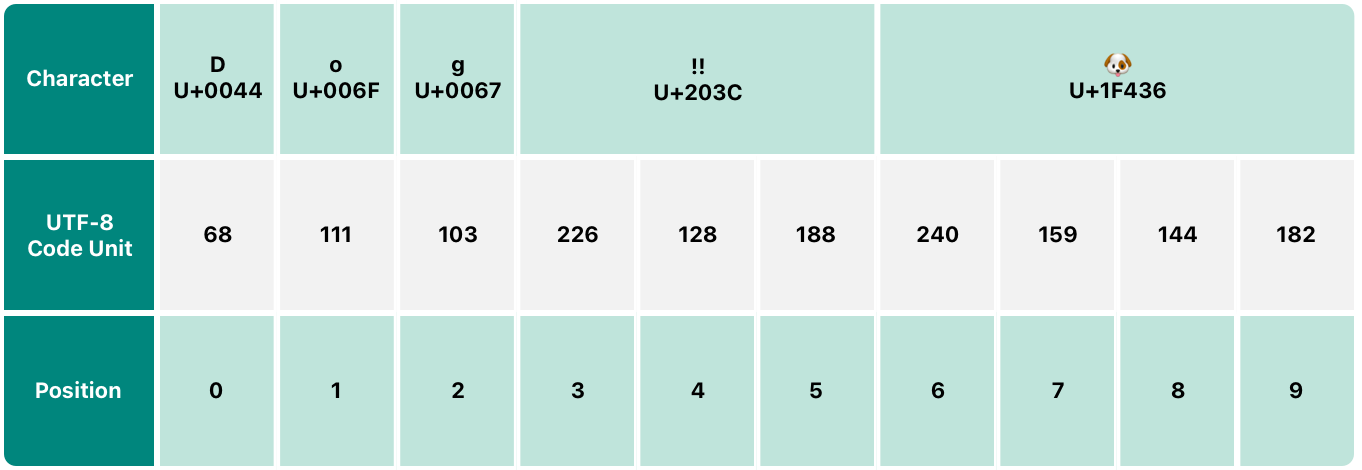
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// 68 111 103 226 128 188 240 159 144 182
上記の例では、最初の 3 つの 10 進数の codeUnit(68、111、103)は、ASCII 表現の D、o、g を UTF-8 表現で表しています。 次の 3 つの 10 進数の codeUnit(226、128、188)は、DOUBLE EXCLAMATION MARK を 3 バイトの UTF-8 表現で表しています。最後の 4 つの codeUnit(240、159、144、182)は、DOG FACE 文字を 4 バイトの UTF-8 表現で表しています。
UTF-16 表現(UTF-16 Representation)
UTF-16 表現には String の utf16 プロパティを使います。このプロパティの型は、String.UTF16View で、符号なし 16 ビット(UInt16)のコレクションで、文字列の UTF-16 表現のそれぞれのバイトを表しています:
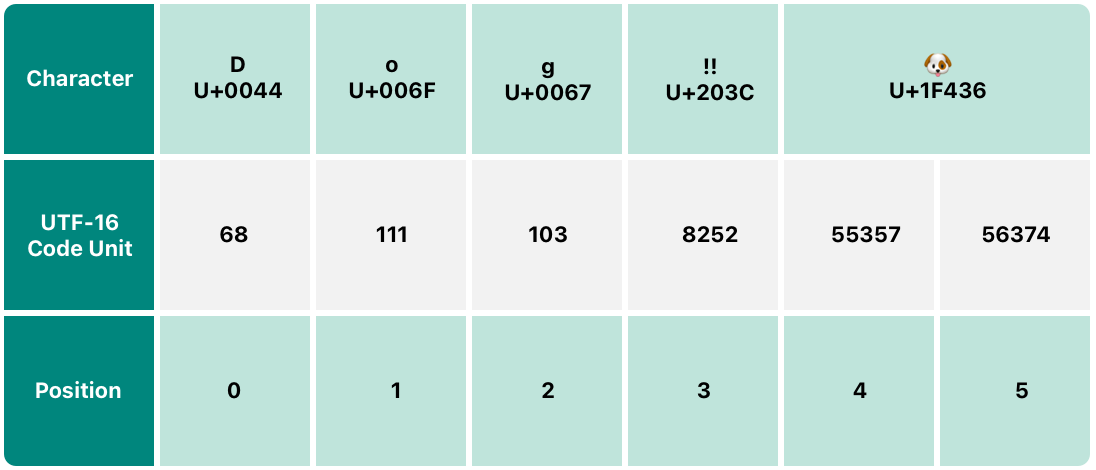
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// 68 111 103 8252 55357 56374
上記の例では、最初の 3 つの 10 進数の codeUnit(68、111、103)は、D、o、g を UTF-16 表現で表しています。これは UTF-8 と同じです。(Unicode スカラは ASCII 文字を表しているため等しくなります)
4 番目の codeUnit(8252)は、16 進数の 203C と等しく、DOUBLE EXCLAMATION MARK(U+203C) を表しています。この文字は UTF-16 だと 1 つのコードユニットで表すことができます。
5,6 番目の codeUnit(55357, 56374)は UTF-16 のサロゲートペアで、DOG FACE 文字を表しています。これは上位サロゲートの U+D83D(10 進数だと 55357)と下位サロゲートの U+DC36(10 進数だと 56374)です。
Unicode スカラ表現(Unicode Scalar Representation)
Unicode スカラ表現には String の unicodeScalars プロパティを使います。このプロパティの型は、UnicodeScalarView で、UnicodeScalar のコレクションです。
それぞれの UnicodeScalar には UInt32 で表される 21 ビットのスカラを返す value プロパティを持っています。
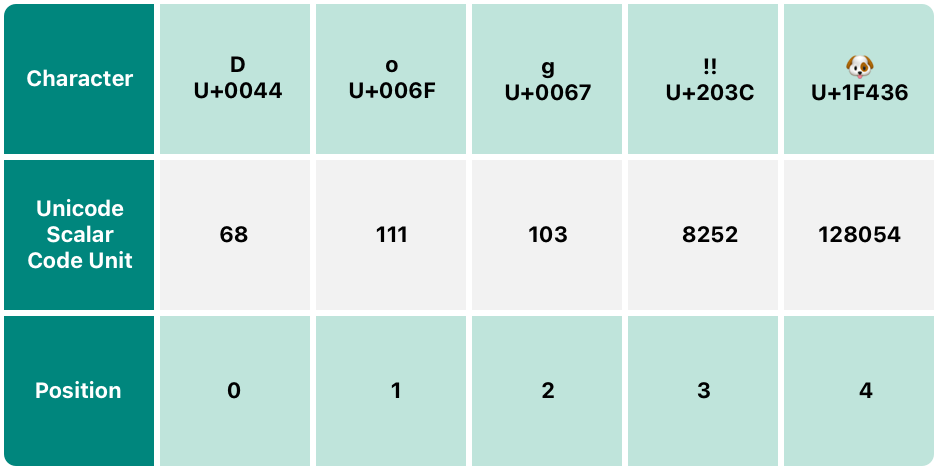
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// 68 111 103 8252 128054
最初の 3 つの UnicodeScalar(68、111、103)の value プロパティは、D、o、g を表しています。
4 番目の codeUnit(8252)は、16 進数の 203C と等しく、DOUBLE EXCLAMATION MARK(U+203C) を表しています。
5 番目の UnicodeScalar(128054)は、16 進数の 1F436 と等しく、DOG FACE 文字を表す Unicode スカラ U+1F436 と等しいです。
value プロパティを探索する代わりに、それぞれの UnicodeScalar 値から新しい String を構築することもできます。例えば文字列補間で使えます:
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶